 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLION: A Clifford Neural Paradigm for Multimodal-Attributed Graph Learning
Jan 29, 2026Recently, the rapid advancement of multimodal domains has driven a data-centric paradigm shift in graph ML, transitioning from text-attributed to multimodal-attributed graphs. This advancement significantly enhances data representation and expands the scope of graph downstream tasks, such as modality-oriented tasks, thereby improving the practical utility of graph ML. Despite its promise, limitations exist in the current neural paradigms: (1) Neglect Context in Modality Alignment: Most existing methods adopt topology-constrained or modality-specific operators as tokenizers. These aligners inevitably neglect graph context and inhibit modality interaction, resulting in suboptimal alignment. (2) Lack of Adaptation in Modality Fusion: Most existing methods are simple adaptations for 2-modality graphs and fail to adequately exploit aligned tokens equipped with topology priors during fusion, leading to poor generalizability and performance degradation. To address the above issues, we propose LION (c\underline{LI}ff\underline{O}rd \underline{N}eural paradigm) based on the Clifford algebra and decoupled graph neural paradigm (i.e., propagation-then-aggregation) to implement alignment-then-fusion in multimodal-attributed graphs. Specifically, we first construct a modality-aware geometric manifold grounded in Clifford algebra. This geometric-induced high-order graph propagation efficiently achieves modality interaction, facilitating modality alignment. Then, based on the geometric grade properties of aligned tokens, we propose adaptive holographic aggregation. This module integrates the energy and scale of geometric grades with learnable parameters to improve modality fusion. Extensive experiments on 9 datasets demonstrate that LION significantly outperforms SOTA baselines across 3 graph and 3 modality downstream tasks.
When LLMs meet open-world graph learning: a new perspective for unlabeled data uncertainty
May 21, 2025Recently, large language models (LLMs) have significantly advanced text-attributed graph (TAG) learning. However, existing methods inadequately handle data uncertainty in open-world scenarios, especially concerning limited labeling and unknown-class nodes. Prior solutions typically rely on isolated semantic or structural approaches for unknown-class rejection, lacking effective annotation pipelines. To address these limitations, we propose Open-world Graph Assistant (OGA), an LLM-based framework that combines adaptive label traceability, which integrates semantics and topology for unknown-class rejection, and a graph label annotator to enable model updates using newly annotated nodes. Comprehensive experiments demonstrate OGA's effectiveness and practicality.
Rethinking Graph Out-Of-Distribution Generalization: A Learnable Random Walk Perspective
May 09, 2025Out-Of-Distribution (OOD) generalization has gained increasing attentions for machine learning on graphs, as graph neural networks (GNNs) often exhibit performance degradation under distribution shifts. Existing graph OOD methods tend to follow the basic ideas of invariant risk minimization and structural causal models, interpreting the invariant knowledge across datasets under various distribution shifts as graph topology or graph spectrum. However, these interpretations may be inconsistent with real-world scenarios, as neither invariant topology nor spectrum is assured. In this paper, we advocate the learnable random walk (LRW) perspective as the instantiation of invariant knowledge, and propose LRW-OOD to realize graph OOD generalization learning. Instead of employing fixed probability transition matrix (i.e., degree-normalized adjacency matrix), we parameterize the transition matrix with an LRW-sampler and a path encoder. Furthermore, we propose the kernel density estimation (KDE)-based mutual information (MI) loss to generate random walk sequences that adhere to OOD principles. Extensive experiment demonstrates that our model can effectively enhance graph OOD generalization under various types of distribution shifts and yield a significant accuracy improvement of 3.87% over state-of-the-art graph OOD generalization baselines.
Toward Data-centric Directed Graph Learning: An Entropy-driven Approach
May 02, 2025



The directed graph (digraph), as a generalization of undirected graphs, exhibits superior representation capability in modeling complex topology systems and has garnered considerable attention in recent years. Despite the notable efforts made by existing DiGraph Neural Networks (DiGNNs) to leverage directed edges, they still fail to comprehensively delve into the abundant data knowledge concealed in the digraphs. This data-level limitation results in model-level sub-optimal predictive performance and underscores the necessity of further exploring the potential correlations between the directed edges (topology) and node profiles (feature and labels) from a data-centric perspective, thereby empowering model-centric neural networks with stronger encoding capabilities. In this paper, we propose \textbf{E}ntropy-driven \textbf{D}igraph knowl\textbf{E}dge distillatio\textbf{N} (EDEN), which can serve as a data-centric digraph learning paradigm or a model-agnostic hot-and-plug data-centric Knowledge Distillation (KD) module. The core idea is to achieve data-centric ML, guided by our proposed hierarchical encoding theory for structured data. Specifically, EDEN first utilizes directed structural measurements from a topology perspective to construct a coarse-grained Hierarchical Knowledge Tree (HKT). Subsequently, EDEN quantifies the mutual information of node profiles to refine knowledge flow in the HKT, enabling data-centric KD supervision within model training. As a general framework, EDEN can also naturally extend to undirected scenarios and demonstrate satisfactory performance. In our experiments, EDEN has been widely evaluated on 14 (di)graph datasets (homophily and heterophily) and across 4 downstream tasks. The results demonstrate that EDEN attains SOTA performance and exhibits strong improvement for prevalent (Di)GNNs.
Rethinking Graph Structure Learning in the Era of LLMs
Mar 27, 2025



Recently, the emergence of large language models (LLMs) has prompted researchers to explore the integration of language descriptions into graphs, aiming to enhance model encoding capabilities from a data-centric perspective. This graph representation is called text-attributed graphs (TAGs). A review of prior advancements highlights that graph structure learning (GSL) is a pivotal technique for improving data utility, making it highly relevant to efficient TAG learning. However, most GSL methods are tailored for traditional graphs without textual information, underscoring the necessity of developing a new GSL paradigm. Despite clear motivations, it remains challenging: (1) How can we define a reasonable optimization objective for GSL in the era of LLMs, considering the massive parameters in LLM? (2) How can we design an efficient model architecture that enables seamless integration of LLM for this optimization objective? For Question 1, we reformulate existing GSL optimization objectives as a tree optimization framework, shifting the focus from obtaining a well-trained edge predictor to a language-aware tree sampler. For Question 2, we propose decoupled and training-free model design principles for LLM integration, shifting the focus from computation-intensive fine-tuning to more efficient inference. Based on this, we propose Large Language and Tree Assistant (LLaTA), which leverages tree-based LLM in-context learning to enhance the understanding of topology and text, enabling reliable inference and generating improved graph structure. Extensive experiments on 10 TAG datasets demonstrate that LLaTA enjoys flexibility - incorporated with any backbone; scalability - outperforms other LLM-based GSL methods in terms of running efficiency; effectiveness - achieves SOTA performance.
Toward Effective Digraph Representation Learning: A Magnetic Adaptive Propagation based Approach
Jan 21, 2025



The $q$-parameterized magnetic Laplacian serves as the foundation of directed graph (digraph) convolution, enabling this kind of digraph neural network (MagDG) to encode node features and structural insights by complex-domain message passing. As a generalization of undirected methods, MagDG shows superior capability in modeling intricate web-scale topology. Despite the great success achieved by existing MagDGs, limitations still exist: (1) Hand-crafted $q$: The performance of MagDGs depends on selecting an appropriate $q$-parameter to construct suitable graph propagation equations in the complex domain. This parameter tuning, driven by downstream tasks, limits model flexibility and significantly increases manual effort. (2) Coarse Message Passing: Most approaches treat all nodes with the same complex-domain propagation and aggregation rules, neglecting their unique digraph contexts. This oversight results in sub-optimal performance. To address the above issues, we propose two key techniques: (1) MAP is crafted to be a plug-and-play complex-domain propagation optimization strategy in the context of digraph learning, enabling seamless integration into any MagDG to improve predictions while enjoying high running efficiency. (2) MAP++ is a new digraph learning framework, further incorporating a learnable mechanism to achieve adaptively edge-wise propagation and node-wise aggregation in the complex domain for better performance. Extensive experiments on 12 datasets demonstrate that MAP enjoys flexibility for it can be incorporated with any MagDG, and scalability as it can deal with web-scale digraphs. MAP++ achieves SOTA predictive performance on 4 different downstream tasks.
Causal Interventional Prediction System for Robust and Explainable Effect Forecasting
Jul 29, 2024



Although the widespread use of AI systems in today's world is growing, many current AI systems are found vulnerable due to hidden bias and missing information, especially in the most commonly used forecasting system. In this work, we explore the robustness and explainability of AI-based forecasting systems. We provide an in-depth analysis of the underlying causality involved in the effect prediction task and further establish a causal graph based on treatment, adjustment variable, confounder, and outcome. Correspondingly, we design a causal interventional prediction system (CIPS) based on a variational autoencoder and fully conditional specification of multiple imputations. Extensive results demonstrate the superiority of our system over state-of-the-art methods and show remarkable versatility and extensibility in practice.
Hierarchical Capsule Prediction Network for Marketing Campaigns Effect
Aug 22, 2022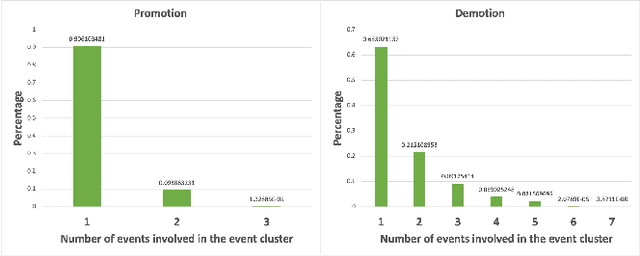
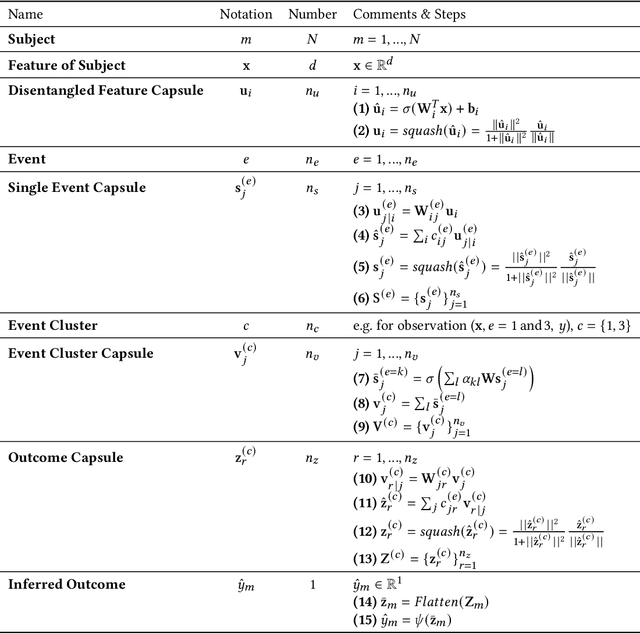
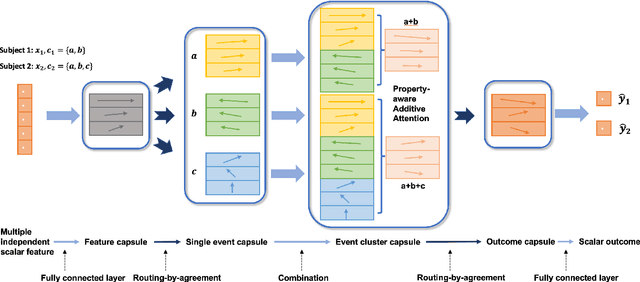
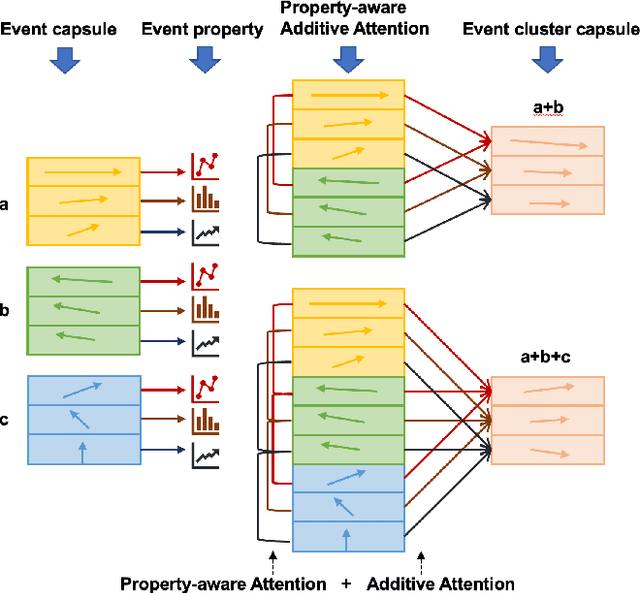
Marketing campaigns are a set of strategic activities that can promote a business's goal. The effect prediction for marketing campaigns in a real industrial scenario is very complex and challenging due to the fact that prior knowledge is often learned from observation data, without any intervention for the marketing campaign. Furthermore, each subject is always under the interference of several marketing campaigns simultaneously. Therefore, we cannot easily parse and evaluate the effect of a single marketing campaign. To the best of our knowledge, there are currently no effective methodologies to solve such a problem, i.e., modeling an individual-level prediction task based on a hierarchical structure with multiple intertwined events. In this paper, we provide an in-depth analysis of the underlying parse tree-like structure involved in the effect prediction task and we further establish a Hierarchical Capsule Prediction Network (HapNet) for predicting the effects of marketing campaigns. Extensive results based on both the synthetic data and real data demonstrate the superiority of our model over the state-of-the-art methods and show remarkable practicability in real industrial applications.
Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention
Apr 29, 2021


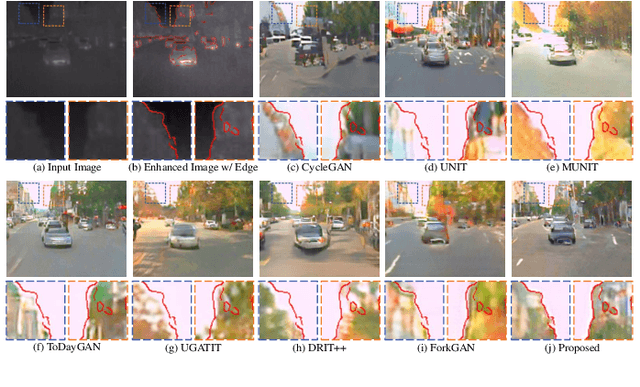
Benefitting from insensitivity to light and high penetration of foggy environments, infrared cameras are widely used for sensing in nighttime traffic scenes. However, the low contrast and lack of chromaticity of thermal infrared (TIR) images hinder the human interpretation and portability of high-level computer vision algorithms. Colorization to translate a nighttime TIR image into a daytime color (NTIR2DC) image may be a promising way to facilitate nighttime scene perception. Despite recent impressive advances in image translation, semantic encoding entanglement and geometric distortion in the NTIR2DC task remain under-addressed. Hence, we propose a toP-down attEntion And gRadient aLignment based GAN, referred to as PearlGAN. A top-down guided attention module and an elaborate attentional loss are first designed to reduce the semantic encoding ambiguity during translation. Then, a structured gradient alignment loss is introduced to encourage edge consistency between the translated and input images. In addition, pixel-level annotation is carried out on a subset of FLIR and KAIST datasets to evaluate the semantic preservation performance of multiple translation methods. Furthermore, a new metric is devised to evaluate the geometric consistency in the translation process. Extensive experiments demonstrate the superiority of the proposed PearlGAN over other image translation methods for the NTIR2DC task. The source code and labeled segmentation masks will be available at \url{https://github.com/FuyaLuo/PearlGAN/}.